内容安全审核成为以短视频、新闻资讯,直播等平台优先级最高的运营需求,不管是通过人工审核还是以系统性的机器审核,都是以最安全与最适合产品的审核结果维度为主。随着国家监管的力度不断提升,暴力、血腥、政治、黄赌毒及危机青少年不良社会导内容向已成为重点关注区域。
常见的违规内容,在文字、图片、音视频很容易被肉眼所捕捉到,对于需要肉眼仔细审核才能会发现内容存在的问题,如文字中携带的形变、音变与直接赤裸显示粗陋内容;图片中常见的血腥、带有讽刺性、暗示性的内容导向;音频波形中杂乱外音包裹的其传达核心无法识别的讯息。视频中常见的漏点、涉黄、及音画不同步现象。而这些违规内容对现在的人工智能科技来讲,识别审核程度较难,且识别效果不准确。若处理类似于藏头诗、漫画图、带有正向文字的负面导向内容,机器更是难上加难。当企业领导为了减轻企业成本,执意采用机器来审核,可能被监管部门抽中的“中奖”几率性会增加很高,毕竟这场博弈,用侥幸的概率去对比约谈甚至关停的企业风险还是有些大的。
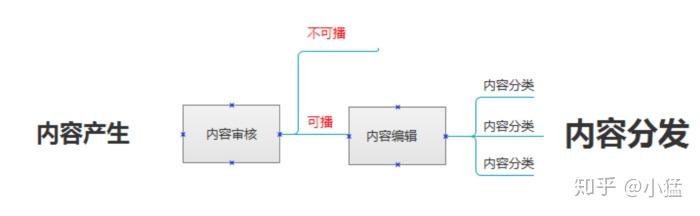
内容审核流程
内容审核常分为两个系统,一个是政治审核系统,一个其他系统审核。企业对于其他的审核条件会根据企业的运营需求调整宽松程度,甚至打擦边球。但对于政治审核来讲,没有企业甘愿冒此风险。内容审核系统基本上就是根据国家法律法规,外加地方网监法律法规,文化部和公安部的政策规定,进行审核的。对于内容审核,第一是相关部门是亲眼看到不良相关性的内容,第二是通过API接口审核排查,不管是地方的网监,还是国家监管部门,都是有一套相关的数据排查系统。政治违规相比其他违规监测更为严格,目前市面上内容审核方案服务商,对政治违规内容判别检测都做到近似100%。(这里普及一个知识:法律法规是已经成文的,就是不能触犯的信息。犯了就是犯罪,必须有行政处罚的。而政策规定只能算是规矩,触犯了根据情节严重,还有中国惯有国情的关系,可以有伸缩的。)
内容安全图像、文字、音视频是如何审核的?什么AI技术呢?这些审核的准确度如何呢? 接着看:
图片审核技术与逻辑:
对于政治人物(图片)的审核,可直接调用服务商的接口,如云净网、图谱科技、数美等,这些服务商已成型的识别技术可判断当前图片是否涉黄,涉政,及违规性指数,满足企业对于图片的审核条件。对于暴力、血腥、漫画这类图片,通常还是需配有人工逐条审核。在对于大并发量的上传情况下,单人审核肯定无法满足先审后发的规定,并可能会对用户体验造成产品不舒适的感觉,引发规模性的流失。而避免这一漏洞,这时,通常就需招聘多人甚至人工审核外包团队进行内容审核管理。
对图片识别技术方式而言,图片的识别一般采用大数据标签学习与相似度对比技术。对于政治人物检测识别则使用AI系统中的人脸识别系统,人脸识别技术被广泛采用的区域特征分析算法,通过深度学习技术从视频和照片中提取人像特征点,利用生物统计学的原理进行分析建立数学模型,即人脸特征模板。在已建成的人脸特征模板与被测者的人的面像进行特征分析,根据分析的结果来给出一个相似度值,最终搜索到最佳匹配人脸特征模板,并因此确定个人的身份信息。
广义的人脸识别实际包括构建人脸识别系统的一系列相关技术:包括图像采集、人脸检测、特征建模、比对辨识、身份确认等;而狭义的人脸识别特指通过人脸进行身份确认或者身份查找的技术或系统。
文本的审核技术与逻辑:
文本的审核要比图片更加多样化及专业化,从文字场景来讲,文字可能是一个签名、一个词组,一段文本甚至是一篇文章,还有些文字附带在图片上,如一张海报,一张头像图等。从内容上分,内容应该分为三种,文字,图形与语言。在文字上来说,国内图书有中图法,国外有亚马逊分类法,高斯分类等。
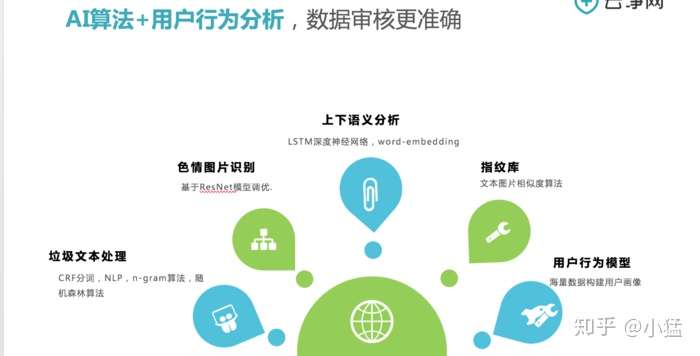
对于图片中存在的文字,识别最多使用的还是OCR(文本识别技术)。对于长短文本及变形变异字体中,会使用到垃圾文本处理技术(在AI技术来讲:CRF分词,NLP,n-gram算法,随机森林算法)随机森林指的是利用多棵树对样本进行训练并预测的一种分类器,通过对文本的处理进行归类,自动预测文本内容的形式。
当你要做预测的时候,新的观察值随着决策树自上而下走下来并被赋予一个预测值或标签。一旦森林中的每棵树都给有了预测值或标签,所有的预测结果将被归总到一起,所有树的投票返回做为最终的预测结果。简单来说,99.9%不相关的树做出的预测结果涵盖所有的情况,这些预测结果将会彼此抵消。少数优秀的树的预测结果将会脱颖而出,从而得到一个好的预测结果。
在对于上下段落中,突然出现的垃圾文本或不相关的文字或词组,会采用上下语义识别技术(LSTM深度神经网络,word-embedding)。此算法技术,会判断此句话中是否跟上下文结合,是否是一段无效的垃圾文本,最常见场景是我们在评论区随意敲打着一串自己都看不懂的文本。此技术很适合用于评论区的灌水,刷屏,甚至辱骂性的文字内容。—以上文本技术请教于云净网CTO许城(云净网是一家内容安全运营服务商)
对于图片的识别,目前单靠机器识别,往往无法满足审核需求,恕我直言,目前阶段机器识别技术只能辅助人工审核,暂无法全面机器审核。AI机器审核还相当于人类三岁的智商,是处于弱智能时代,为了增强内容审核安全及无延迟的用户体验,建议企业还是组建人工审核团队。
语音识别技术与能力
语音在专业角度划分为两种:音频与视频。
语音(音频)识别的应用场景较多,比如AI智能音响常用到的语音识别,电话通话视频中的语音视频,甚至是直播平台中主播在讲的音频内容。音频等于说话,说话包含说了什么?(涉政、涉黄、涉赌还是广告信息)。
在音频技术识别方面,针对不同的内容有不同识别技术。针对说话内容有语音识别、关键词检索等;针对语种的判别有语种识别的技术;针对说话人的识别有声纹识别技术;针对说话内容无关的通常采用音频比对的技术来进行检测。通常一般短视频,直播或者音频平台,对音频对比、声纹的技术较为重视,是保证录音质量及外放声音很有效的一种运营手段,但对内容语音识别,则不太关注,毕竟语音识别技术对这些企业的应用场景不是刚需。
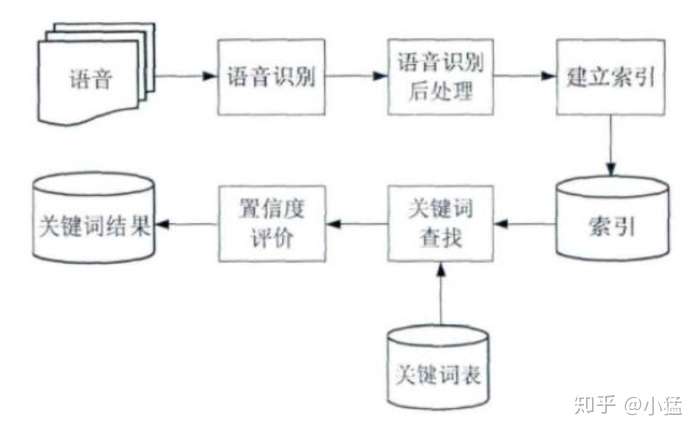
*图源于网络
基于语音识别的关键词检索是将语音识别的结构构建成一个索引网络,然后把关键词从索引网络中找出来。从上图流程中可以看到,首先把语音进行识别处理,从里面提取索引构建索引网络,进行关键词检索的时候,在通过关键词表在网络中进行频率,找到概率最高的,输出其关键词匹配结果。(在这一步可通过垃圾文本处理及上下语义分,对转化的文本进行处理)
目前音频的识别技术能力还远远达不到准确阶段,比如音频出现的“娇喘声”单靠技术根本无法识别,或识别(转化)出来就是一串乱字。再如在人潮拥挤的杂音中,出现的音频,也无法准确的转化成文字识别。遇到这种隐晦场景下的文本,通常还是需要人工去审核。
视频识别技术与处理模式:
在视频上,根据内容不同,如直播、短视频、个人上传的视频,视频是画面与音频组成的以帧为单位的画面。对于音频常存在暴恐、淫秽传播、甚至是音画不同步等问题。在视频处理上面,通常采用截帧上传服务器数据对比来识别。其审核模式与图片审核相同,会判断场景(外室外还是室内)、会判断人脸(画面中出现的人是否是明星或者政治)、会判断是否色情(根据画面图片的裸露状态,可为正常、性感、色情等不同唯独)。
如抖音、映客、等以视频流为主的APP,对视频内容的审核往往通过机器的方式进大量的审核筛检,画面中存在的严重血腥、暴恐、色情、政治新闻等危害画面内容会优先被干掉,而那些不以直接性的画面展示的内容机器难以审查出来。
讲了这么多,内容违规存在的音、视、图、文,以技术的识别方式都是通用的,只不过在审核时设定的策略及宽进程度不同,如图片的识别,可设定存有性感,但不能色情,也可设置存有只能人脸,但不能物体,拦截的宽紧程度需要人工来设定,对于大量的内容并发,则是需要大量人工通过机器辅助人工进行审核,而非机器单独进行全方位过滤。
内容审核技术与逻辑不单单是套系统,而非一套非常的准确且严谨的工作,内容审核既要及时拦截违规内容信息,又不能对用户造成产品上的体验落差。内容审核,任重而道远。